Pyface DataViews¶
The Pyface DataView API allows visualization of hierarchical and non-hierarchical tabular data.
Note
As of Pyface 7.1.0, the public API for DataView is provisional and may change in the future minor releases through until Pyface 8.0
Indexing¶
The DataView API has a consistent way of indexing that uses tuples of integers to represent the rows and columns, as illustrated below:
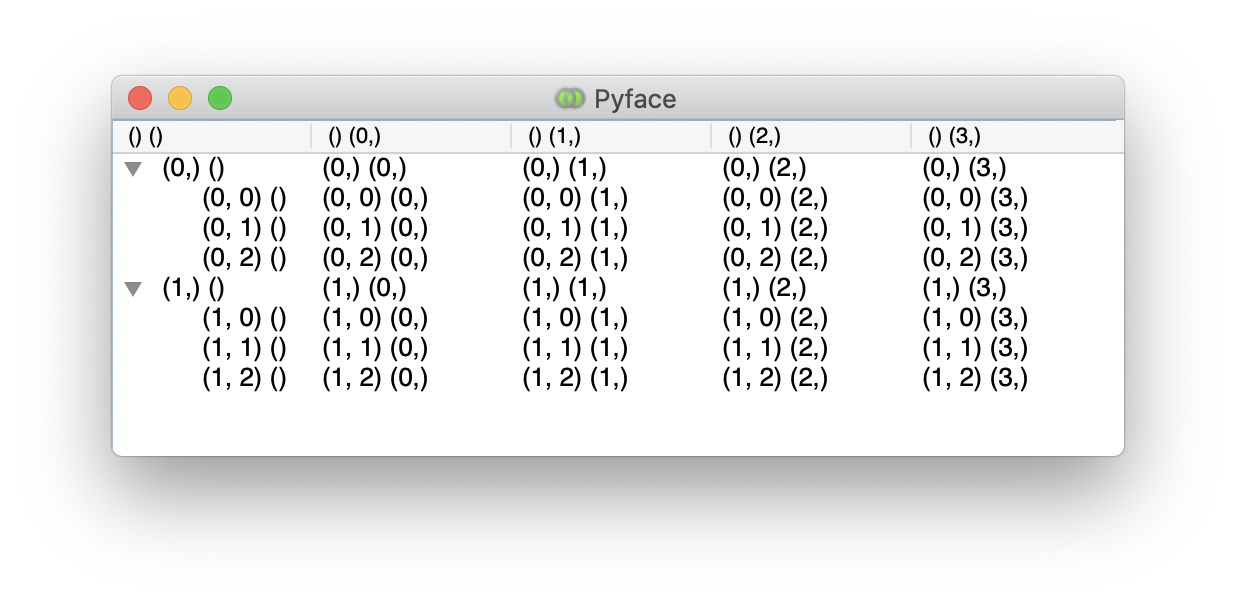
How DataView Indexing Works.¶
A row index corresponds to a list of integer indexes at each level of the
hierarchy, so the empty tuple () represents the root of the hierarchy,
the tuples (0,) and (1,) give the two child rows of the root, while
(0, 1) is the second child row of the first child of the root, and so on.
Column indices follow a similar pattern, but only have the root and one level of child indices.
When interpreting these values, the root row () corresponds to the
column headers, the root column () corresponds to the row headers.
The root row and column indices together refer to the cell in the top-left
corner.
Selections¶
Implementers of the IDataViewWidget interface provide a selection trait
that holds a list of tuples of selected row and column index values. This
trait is settable, so changes made to the trait are reflected in the selection
in the view.
The selection_type trait describes what gets selected when a user clicks
on a cell. It defaults to row, which selects entire rows with one click,
but implementations may optionally support item and column selection
as well.
In row selection type, the column values are all equal () (in other
words, the indices of the appropriate row header), and users setting the
values should adhere to that expectation.
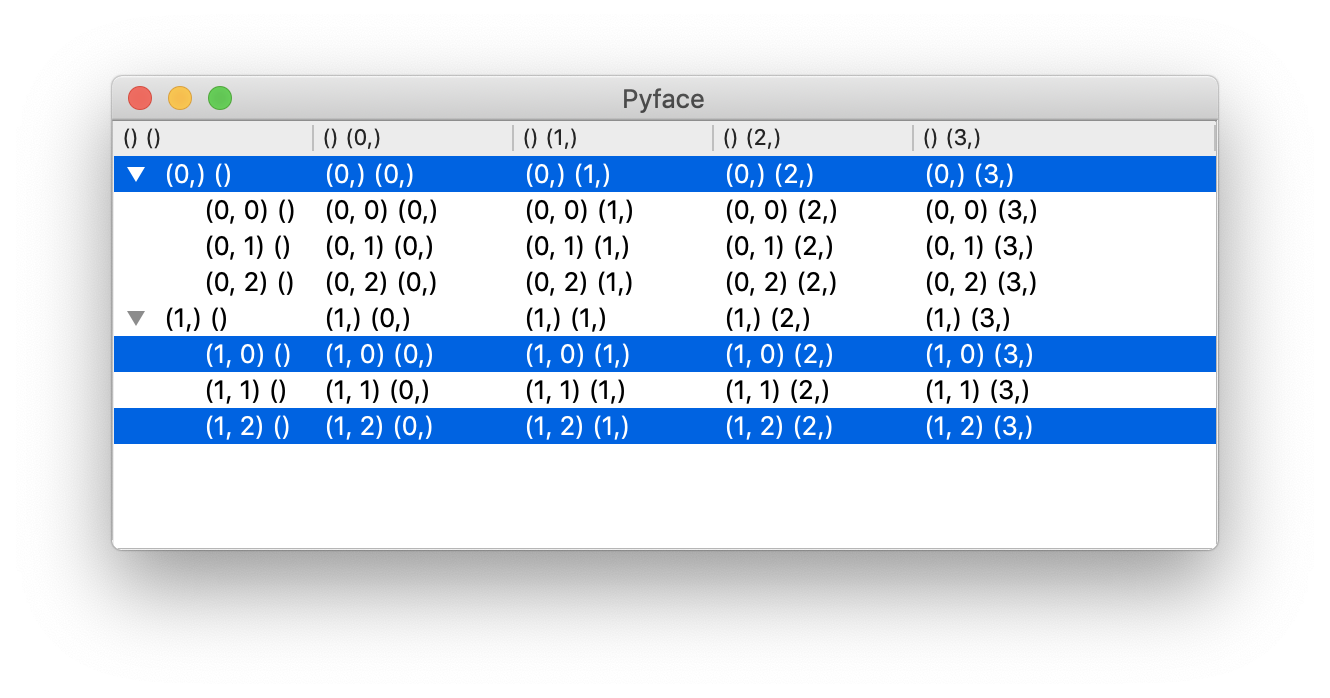
Row selection type.¶
This corresponds to the selection being set equal to
[((0,), ()), ((1, 0), ()), ((1, 2), ())].
The column selection type only selects the column values that are children
of a particular parent row, and so the row provided is that parent row. Code
which sets the value of the selection should adhere to that expectation.
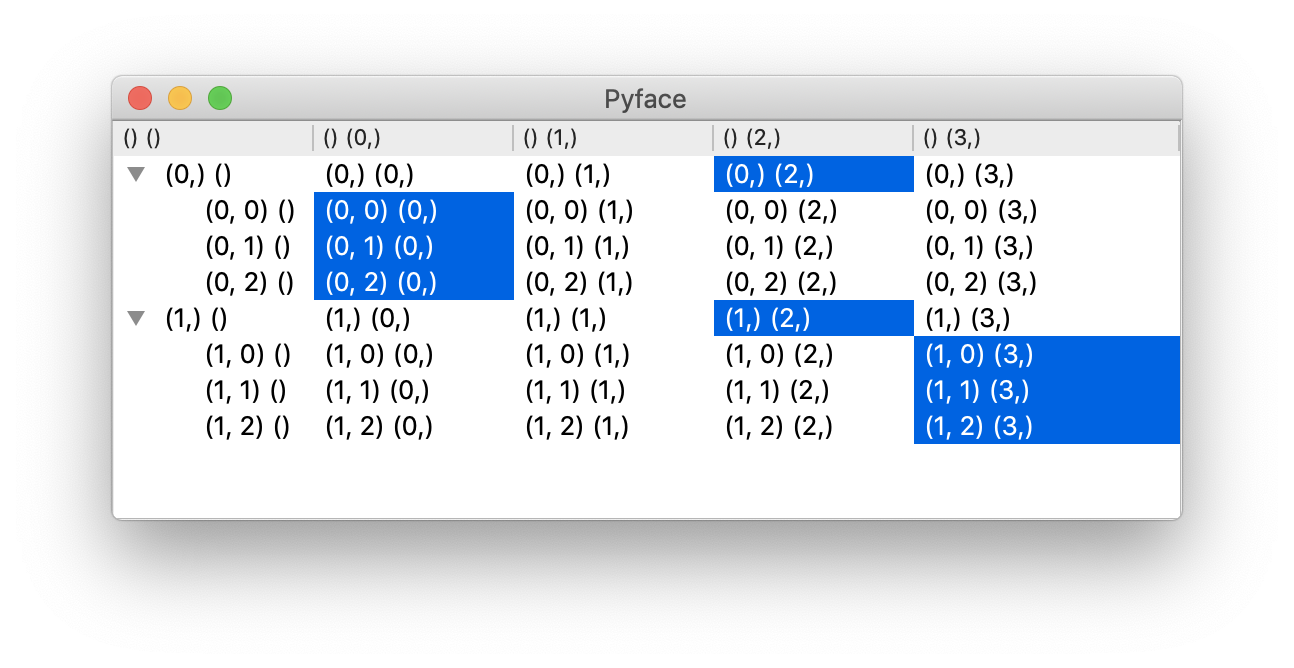
Column selection type.¶
This corresponds to the selection being set equal to
[((), (2,)), ((0,), (0,)), ((1,), (3,))].
The item selection type potentially allows any index, specified by both,
row and column indices. This can include row and column headers provided that
the view supports selecting them (which is likely dependent on the underlying
toolkit and platform’s capabilities); in these cases the selected values are
just the values in the header cells, not the entire row or column.
The selection_mode trait describes the behaviour of selections as the user
interacts with them. It defaults to extended, which allows the user to
extend the selection by shift-clicking or other similar platform-dependent
interactions, but can also take the value single, which restricts the
user to at most one selected thing.
A change to either the selection_type or the selection_mode results in the
selection be cleared.
Note: with the current implementations, the selection list should not be
mutated, rather the entire list should be replaced on every change. This
restriction may be relaxed in the future.
Drag and Drop¶
The IDataViewWidget interface provides hooks to support dragging the
selected values out of the table, or dropping objects onto the data view.
To provide cross-platform and cross-toolkit compatibility, drag and drop
operations require the data that is being exported or imported to be
converted to or from a bytestring in some MIME type.
The DataView infrastructure provides a DataFormat named tuple to
encapsulate the process of converting different data objects to bytes.
For string objects this conversion might be as simple as encoding the
text as UTF-8 and declaring it to be a text/plain MIME type, but for
more complex structures there is serialization and deserialization which
needs to occur. The DataFormat objects are expected to provide the
mimetype of the data, a function to serialize an object, and a function
to deserialize bytes.
In practice the sorts of objects being dragged and dropped, can be classified as simple scalar values (such as might occur when the selection is a single item), 1D collections of values (such as might occur when multiple items are selected, or a single row or column is selected), or 2D collections of values (such as might occur for extended row or column selections).
The DataView api provides a standard data formats for plain text, CSV,
and .npy format for scalar, 1D and 2D exports; HTML and JSON formats
for scalar values, as well as standard serializers and deserializers
for users to create build their own DataFormat instances if the defaults
do not match the needs.
Dragging¶
To allow dragging the selection, the exporters trait should hold a list
of AbstractDataExporter instances. This class provides methods to access
the values to be exported from the selected indices, as well as a reference
to a DataFormat that will perform the actual serialization and provides
the MIME type.
In practice, users will usually use a standard data exporter, such as the
ItemExporter or RowExporter. Some care should be taken that
the data exporter provides data in the shape that the DataFormat expects.
For example, the ItemExporter works best when paired with scalar data
formats. In many cases all that is needed to enable dragging data from a
DataViewWidget is to configure it appropriately:
control = DataViewWidget(
...,
selection_mode='extended',
exporters=[
RowExporter(format=table_format),
RowExporter(format=csv_format),
],
...
)
When multiple exporters are provided, _all_ of the supported formats are exported as part of the drag operation, and it is up to the target program to decide which of the supplied formats it can best handle, if any.
Dropping¶
The IDataViewWidget supports dropping of objects via the IDropHandler
interface supported by other widgets. Developers using DataViews can
handle dropped data by providing a list of IDropHandler instances which
tell the underlying code whether the objects being dropped can be dropped,
and if so, how to handle the drop operation.
For example, to handle files being dropped onto the DataView, a DataView could
use the generic FileDropHandler class, coupled with a callback to load the
data from the dropped file.
control = DataViewWidget(
...,
drop_handlers=[
FileDropHandler(
extensions=['.csv', '.tsv', '.npy'],
open_file=self.load_data,
)
],
...
)
When multiple drop handlers are supplied, the first one which says it can handle the dropped objects is the one which is used.
There are currently no specific drop handlers for supporting dragging data within the table, but this can be supported by custom drop handlers that use toolkit code to interact with the underlying toolkit objects.
Index Managers¶
These indices need to be converted to and from whatever system the backend
toolkit uses for indexing and tracking rows. This conversion is handled
by an AbstractIndexManager instance. Pyface provides two of these which
efficiently handle the two common cases: TupleIndexManager is designed to
handle general hierarchical models, but needs to cache mementos for all rows
with children (and on Wx, for all rows); the IntIndexManager can only handle
non-hierarchical tables, but does so without needing any additional memory
allocation.
Unless you are creating a toolkit model or widget that uses the DataView
infrastructure it is sufficient to simply know to use the IntIndexManager
when you know that the data will always be a flat table, and TupleIndexManager
otherwise.
Data Models¶
Data to be viewed needs to be exposed to the DataView infrastructure by
creating a data model for it. This is a class that implements the
interface of AbstractDataModel to display values from a dictionary.

The DictDataModel example.¶
The basic traits for the model might look like this:
class DictDataModel(AbstractDataModel):
""" A data model that provides data from a dictionary. """
#: The dictionary containing the data.
data = Dict()
#: The index manager. Because the data is flat, we use the
#: IntIndexManager.
index_manager = Instance(IntIndexManager, ())
The base AbstractDataModel class requires you to provide an index manager
so we use an IntIndexManager because the data is non-hierarchical for this
model.
Data Structure¶
The get_column_count() method needs to be implemented to tell the toolkit
how many columns are in the data model. For the dict model, keys are
displayed in the row headers, so there is just one column displaying the
value:
def get_column_count(self):
return 1
We can signal to the toolkit that certain rows can never have children
via the can_have_children() method. The dict data model is
non-hierarchical, so the root has children but no other rows will ever
have children:
def can_have_children(self, row):
return len(row) == 0
We need to tell the toolkit how many child rows a particular row has,
which is done via the get_row_count() method. In this example, only the
root has children, and the number of child rows of the root is the length
of the dictionary:
def get_row_count(self, row):
if len(row) == 0:
return len(self.data)
return 0
Data Values¶
The get_value() method is used to return the raw value for each location.
To get the values of the dict data model, we need to determine from the row
and column index whether or not the cell is a column header and whether
it corresponds to the keys or the values. The code looks like this:
def get_value(self, row, column):
if len(row) == 0:
# this is a column header
if len(column) == 0:
# title of the row headers
return self.keys_header
else:
return self.values_header
else:
row_index = row[0]
key, value = list(self.data.items())[row_index]
if len(column) == 0:
# the is a row header, so get the key
return key
else:
return value
Conversion of values into data channels is done by providing a value type
for each cell that implements the AbstractValueType interface. The
get_value() method is expected to provide an appropriate data
type for each item in the table. For this data model we have three value
types: the column headers, the keys and the values.
#: The header data channels.
header_value_type = Instance(AbstractValueType)
#: The key column data channels.
key_value_type = Instance(AbstractValueType)
#: The value column data channels.
value_type = Instance(AbstractValueType)
The default values of these traits are defined to be TextValue instances.
Users of the model can provide different value types when instantiating,
for example if the values are known to all be integers then IntValue
could be used instead for the value_type trait:
model = DictDataModel(value_type=IntValue())
The get_value() method uses the indices to select the appropriate
value types:
def get_value_type(self, row, column):
if len(row) == 0:
return self.header_value_type
elif len(column) == 0:
return self.key_value_type
else:
return self.value_type
The AbstractValueType interface provides getters (and in some cases setters)
for various data channels the most obvious of these is the text to display
in an item, but channels allow checked state, image, color and tooltips
to also be associated with a value. How (or even if) these values are
displayed or used is up to the implementation of the IDataViewWidget.
As noted above, the DataView API provides a number of pre-definited value type implementations that cover common cases, but where they do not meet the needs of a particular design, developers should create their own implementations with the desired properties.
Invalid Values¶
If no valid value can be generated for some expected reason, value
generation code can raise a DataViewGetError exception. This error
will be handled and silently ignored by the DataView code, and no value
will be displayed. Any other errors raised by value generation are
assumed to be unexpected and will be logged and re-raised, which is
likely to cause an application crash.
Handling Updates¶
The AbstractDataModel class expects that when the data changes, one of
two trait Events are fired. If a value is changed, or the value type is
updated, but the number of rows and columns is unaffected, then the
values_changed trait should be fired with a tuple:
(start_row_index, start_column_index, end_row_index, end_column_index)
If a major change has occurred, or if the size, shape or layout of the data
has changed, then the structure_changed event should be fired with a
simple True value.
While it is possible that a data model could require users of the model to manually fire these events (and for some opaque, non-traits data structures, this may be necessary), where possible it makes sense to use trait observers to automatically fire these events when a change occurs.
For example, we want to listen for changes in the dictionary and its items.
It is simplest in this case to just indicate that the entire model needs
updating by firing the structure_changed event 1:
@observe('data.items')
def data_updated(self, event):
self.structure_changed = True
Changes to the value types also should fire update events, but usually these are simply changes to the data, rather than changes to the structure of the table. All value types have an updated event which is fired when any state of the type changes. We can observe these, compute which indices are affected, and fire the appropriate event.
@observe('header_value_type.updated')
def header_values_updated(self, event):
self.values_changed = ([], [], [], [0])
@observe('key_value_type.updated')
def key_values_updated(self, event):
self.values_changed = ([0], [], [len(self.data) - 1], [])
@observe('value_type.updated')
def values_updated(self, event):
self.values_changed = ([0], [0], [len(self.data) - 1], [0])
Editing Values¶
A model can flag values as being modifiable by implementing the
can_set_value() function. The default implementation simply returns
False for all items, but subclasses can override this to permit
modification of the values. For example, to allow modification of the
values of the dictionary, we could write:
def can_set_value(self, row, column):
return len(row) != 0 and len(column) != 0
A corresponding set_value() method is needed to actually perform the changes
to the underlying values. If for some reason it is impossible to set the
value (eg. an invalid value is supplied, or set_value() is called with an
inappropriate row or column value, then a DataViewSetError should be
raised:
def set_value(self, row, column, value):
if self.can_set_value(row, column):
row_index = row[0]
key = list(self.data)[row_index]
self.data[key] = value
else:
raise DataViewSetError()
Even though a data value may be modifiable at the data model level, the
value types also have the ability to control whether or not the value is
editable. For example, subclasses of EditableValue, such as TextValue
and IntValue have an is_editable trait that controls whether the
value should be editable in the view (presuming that the underlying value
can be set). Other value types can simply prevent editing by ensuring that
the has_editor_value() method returns False.
Footnotes
- 1
A more sophisticated implementation might try to work out whether the total number of items has changed, and if not, the location of the first and last changes in at least some of the change events, and then fire
values_changed. For simplicty we don’t try to do that in this example.